AI is moving from experimentation to expectation.
More and more organizations are no longer asking if they should use AI, but how to make it work in a reliable and scalable way.
That shift changes the conversation.
Where the focus was initially on models and tooling, it is now increasingly about something else: control, clarity, and trust in the underlying data.
Across many discussions in the past year, one insight keeps returning:
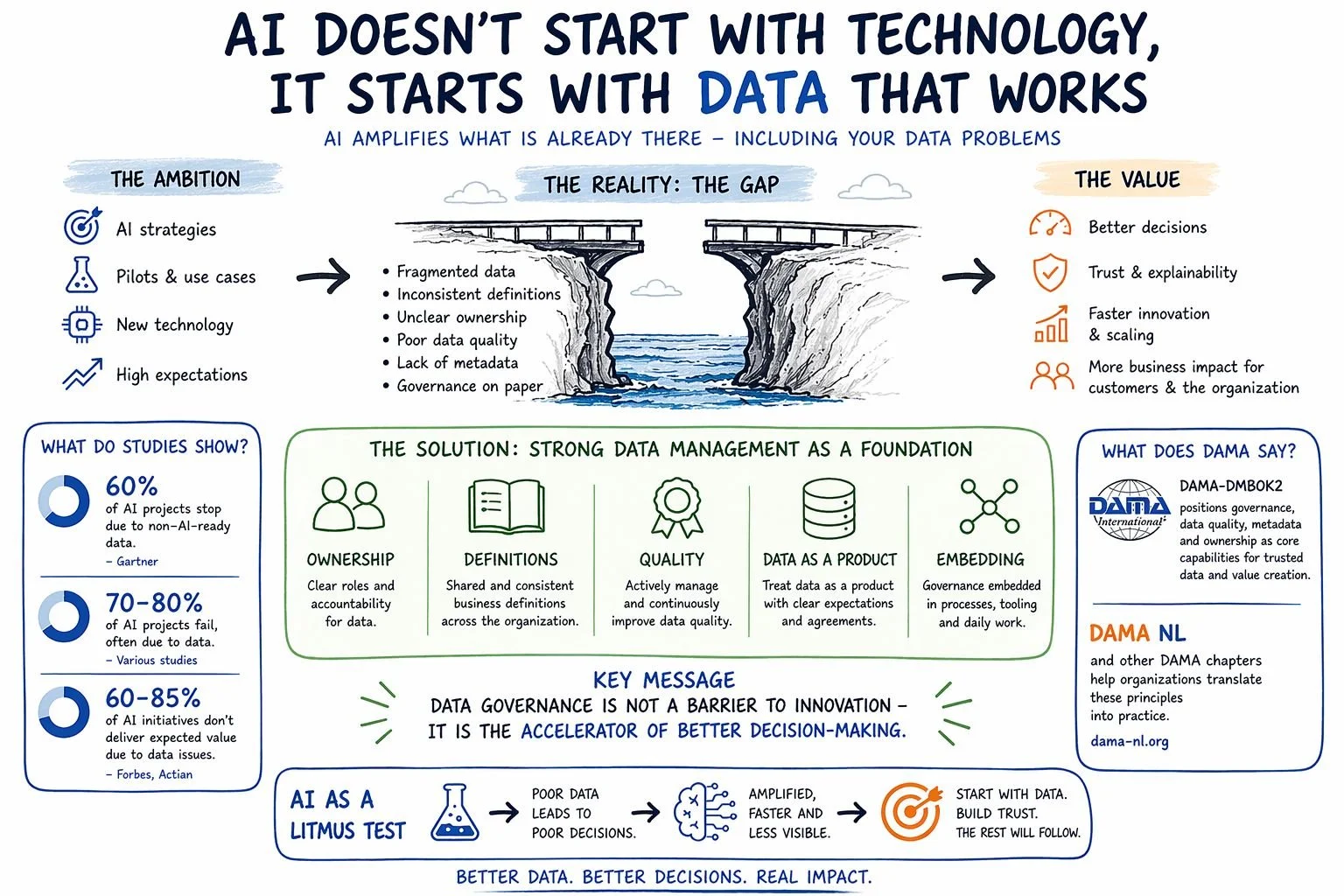
AI does not operate in isolation.
It reflects how well your data is organized.
When data is well defined, owned, and managed, AI can accelerate decision-making and innovation.
When it is not, the outcomes become harder to explain, trust, and scale.
This is where the role of data management becomes more visible again — not as theory, but as a practical capability.
Not as governance for the sake of control,
but as a way to create direction and confidence: clear ownership, shared definitions, reliable data quality, embedded ways of working.
These are not constraints.
They are the conditions that allow AI to deliver real value.
Organizations that recognize this are starting to move differently.
They are not separating data and AI, but treating them as part of the same system.
👉 AI doesn’t start with technology.
It starts with data that works.
And ultimately:
👉 Control over data creates trust in AI.