Verslag DWBI Summit 2026

100 dataprofessionals kwamen samen in Utrecht tijdens de jaarlijkse DWBI Summit van Adept Events.
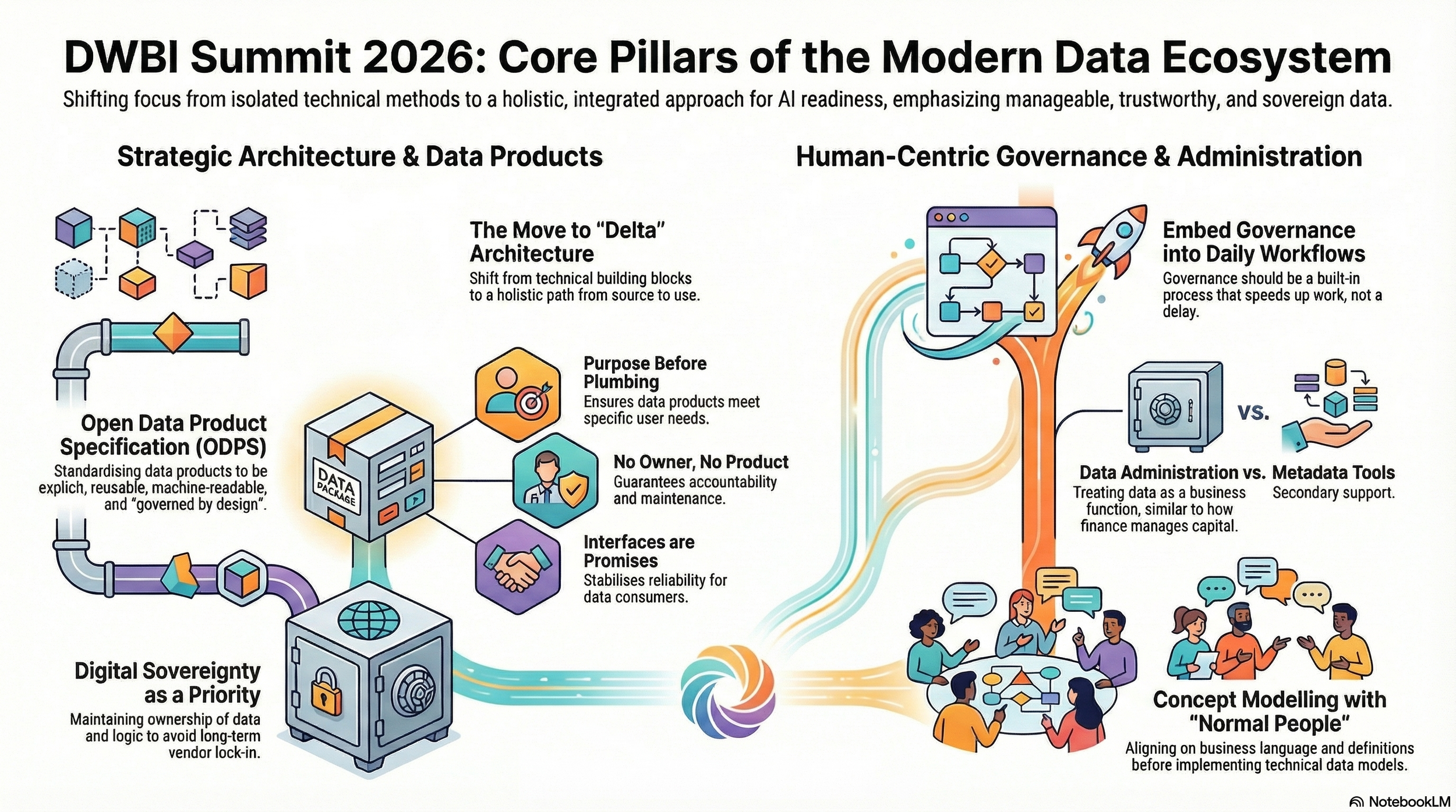
De kernboodschap van de sessies die ik volgde tijdens de DWBI Summit 2026.
Dinsdag 24 maart 2026 was ik aanwezig op de jaarlijkse DWBI Summit van Adept Events, georganiseerd door Werner Schoots en zijn team. Met 100 dataprofessionals in de zaal, veel bekenden uit mijn eigen netwerk en aansprekende groep van sprekers op het programma heb ik een aangename en leerzame dag gehad.
Sinds 1996 kom ik regelmatig op de seminars en congressen van Adept Events en haar voorlopers, als spreker en bezoeker en het stelt me zelden teleur. Ook deze dag was inhoudelijk (sessies van 1 uur, dus niet alleen maar snelle quotes), behandelde actuele thema’s in ons vakgebied (o.a. data soevereiniteit, open data, transparantie en schaalbaarheid in data architectuur, praktische & bewezen aanpakken voor data governance & data management en datamodelleren) wat ik echt kon waarderen: dit soort thema’s, met de nadruk op het beheren van data, staan onder druk van de voortdurende aandacht voor AI. Terwijl Data en AI onlosmakelijk met elkaar verbonden zijn.
Wat op deze editie van de DW & BI Summit vooral zichtbaar werd, is dat het datavak steeds minder draait om losse methoden en technieken en steeds meer om samenhang. Onder verschillende invalshoeken ging het uiteindelijk steeds weer over dezelfde vraag: hoe maak je data beheersbaar, bruikbaar en betrouwbaar in een landschap dat complexer wordt en waarin verantwoordelijkheden niet altijd duidelijk zijn, worden genomen en steeds diffuser dreigen te raken? Juist daarin zat de kracht van deze dag. Niet in een stoet van nieuwe beloftes, maar in een reeks sessies die elk op hun eigen manier teruggingen naar de basis van het vak.
Rick van der Lans opende met een verhaal dat die lijn direct scherp neerzette. Zijn pleidooi voor een holistische data-architectuur (“Delta”) ging niet over nog een extra platformlaag, maar over het opnieuw doordenken van het volledige pad van bron tot gebruik op basis van Transformers. Dat is een wezenlijk verschil. Veel organisaties spreken nog steeds over data-architectuur als een verzameling technische bouwblokken, terwijl de echte opgave elders ligt: samenhang organiseren tussen opslag, integratie, beschikbaarheid, historie, beveiliging, transparantie en betekenis op een zodanige wijze dat hergebruik eenvoudig werkt, vindbaarheid is gegarandeerd en de algehele snelheid van ontwikkelen van oplossingen sterk wordt verhoogd, ook om de snelheid van de veranderingen in de business bij te kunnen houden.

Impressie van de presentatie van Rick van der Lans over de Delta architectuur.
De sessie van Ron Tolido sloot daar op een interessante manier op aan. Zijn verhaal draaide om The 5 Lessons of the Open Data Product Specification. ODPS werd gepositioneerd als een open standaard voor data products, inmiddels ondergebracht bij de Linux Foundation, met als doel data products explicieter, herbruikbaar, bestuurbaar en machineleesbaar te maken. De vijf kernlessen werden helder benoemd: purpose before plumbing, no owner, no product, interfaces are promises, trust is engineered en governance by design. Ook werd zichtbaar hoe ODPS deze lessen vertaalt naar onderdelen als productdetails, strategie, owner/domain, contract en access, service levels en governance policies.
Juist die insteek maakte deze sessie relevant. Het denken in data products is de afgelopen jaren snel populair geworden, maar blijft in de praktijk vaak hangen in slogans. Tolido liet zien dat een data product pas betekenis krijgt als het veel explicieter wordt gespecificeerd. Wat is het precies? Voor wie bestaat het? Wie is eigenaar? Via welke interfaces wordt het aangeboden? Welke kwaliteit en service levels mogen gebruikers verwachten? En welke governance is erin ingebouwd? Dat zijn geen bijzaken, maar precies de elementen die bepalen of een data product werkelijk bestuurbaar en herbruikbaar is. Zijn vergelijking met het shampooflesje van Andrelon was hilarisch.
Sterk was ook dat de sessie het begrip ‘product’ niet romantiseerde. Integendeel: uit de illustraties en voorbeelden sprak juist de waarschuwing dat veel zogenoemde data products nog te vaak een rommelige verzameling datasets, koppelingen en impliciete aannames zijn, met onduidelijk eigenaarschap en beperkte kwaliteitsgaranties. Dan is de term product eerder ambitie dan werkelijkheid.
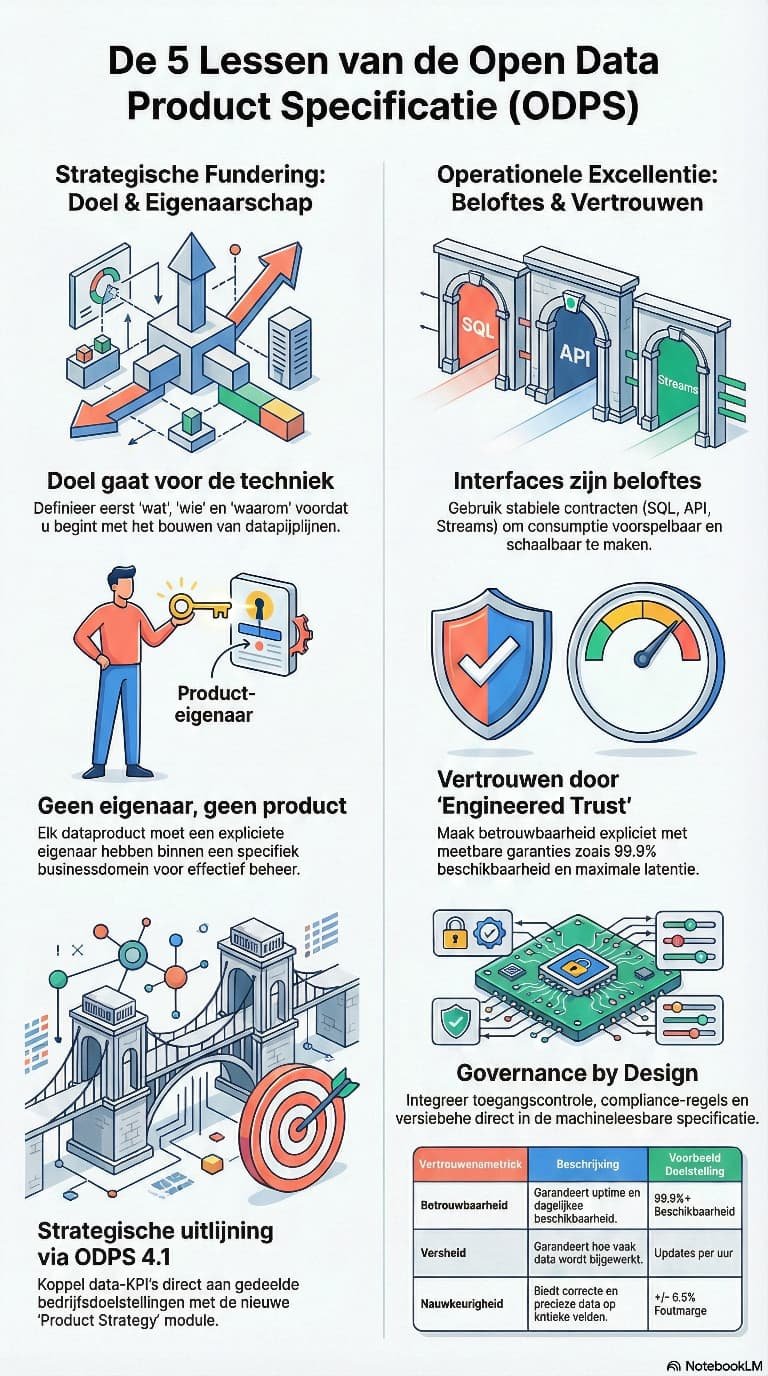
Impressie van de presentatie van Ron Tolido over de Open Data Product Specification.
De sessie van Mathias Vercauteren sloot daar inhoudelijk naadloos op aan, maar dan vanuit governance. Zijn centrale punt was even eenvoudig als raak: data governance faalt vaak niet omdat organisaties het belang ervan niet zien, maar omdat ze het verkeerd organiseren. Governance wordt nog te vaak ingericht als iets extra’s. Een apart programma, een aanvullende overlegstructuur, een laag beleid bovenop de praktijk. Daarmee wordt governance ervaren als vertraging, terwijl het juist zou moeten helpen om sneller en beter te werken.
Dat is een herkenbare observatie. In veel organisaties bestaan rollen, definities, standaarden en beleidsdocumenten inderdaad wel, maar vooral op papier. De business voelt dan weinig eigenaarschap en ervaart governance vooral als administratieve last. De waarde blijft abstract, terwijl de dagelijkse praktijk gewoon doorgaat. De kracht van deze sessie zat in het blootleggen van precies dat probleem. Governance moet niet naast het werk worden gezet, maar in het werk worden ingebouwd.
Daarmee werd governance ook weer teruggebracht naar zijn werkelijke functie. Niet als controlelaag achteraf, maar als manier om verantwoordelijkheden, definities en besluitvorming zó te organiseren dat het dagelijkse werk beter verloopt. Zodra governance losstaat van de praktijk, verliest zij legitimiteit. Zodra zij in processen, rollen en afspraken wordt ingebouwd, ontstaat pas echte werking.

Impressie van de sessie van Mathias Vercauteren over de Data Governance Sprint methode.
Na de lunch kwam in de sessie van Wouter van Aerle een thema naar voren dat vaak minder aandacht krijgt, maar in werkelijkheid fundamenteel is: data-administratie. Zijn verhaal was sterk omdat het het debat meteen uit de gebruikelijke technologiehoek haalde. De kern van zijn betoog was dat veel organisaties hun data niet zozeer slecht managen vanwege een gebrek aan tools, maar vanwege een gebrek aan administratie. Wie data wil beheren, moet eerst weten over welke data het gaat, welke eigenschappen die data hebben, waar ze worden gebruikt en onder welke afspraken, definities en verantwoordelijkheden ze vallen.
Dat klinkt basaal, maar precies daar gaat het in veel organisaties mis. Informatie over definities, modellen, rollen, kwaliteit, AVG, leveringsafspraken en gebruik is vaak verspreid over losse registraties, repositories, spreadsheets en informele overzichten. Dan ontstaat onvermijdelijk versnippering. Niet omdat mensen niets doen, maar omdat er geen integraal systeem is dat de gegevenshuishouding zelf beheersbaar maakt.
Zijn kritiek op de dominante metadata-benadering was daarom terecht. Zodra een vraagstuk uitsluitend als metadata-management wordt geframed, verschuift de aandacht al snel naar tooling, catalogi en repositories. Maar daarmee is het beheersvraagstuk nog niet opgelost. Data-administratie positioneert het probleem veel scherper: dit gaat niet primair over techniek, maar over het organiseren van een bedrijfsfunctie. In die zin was de vergelijking raak: wat een financieel systeem is voor de CFO, zou een data-administratie voor de CDO moeten zijn.
Een concreet praktijkvoorbeeld is het JenV Afsprakenstelsel Gegevens & Algoritmes (JAGA). Deze "Gegevensboekhouding JenV" was finalist voor de prijs "Beste Overheidsinnovatie 2025", waarbij de jury sprak van een "gegevensbeheer-revolutie".
Voor de toekomst wordt gekeken naar een Rijksbrede Gegevensboekhoudstandaard, mogelijk verankerd in een wet. Ook wordt AI gezien als een belangrijke versneller om administratieve taken, zoals het classificeren van data en het afleiden van definities, te automatiseren.

Impressie van de presentatie van Wouter van Aerle over Data Administratie.
De sessie van Antoine Stelma bracht die lijn vervolgens samen op architectuurniveau. Zijn verhaal over een private en soevereine data- en cloudomgeving ging nadrukkelijk verder dan infrastructuur alleen. Natuurlijk kwamen cloud-agnostisch ontwerpen, beveiliging, compliance, lineage, datacatalogi en toolkeuzes aan bod. Maar onder die technische laag zat een veel principiëlere boodschap: organisaties moeten de regie over data, logica en oplossingen niet uit handen geven als zij duurzaam bestuurbaar willen blijven.
Dat maakt dit onderwerp actueler dan ooit. In een tijd waarin veel organisaties onder druk van nieuwe technologische mogelijkheden snelle platformbesluiten nemen, groeit ook het risico van nieuwe afhankelijkheden. De verleiding is groot om snelheid te kopen via gesloten ecosystemen en schijnbaar complete platformen. Maar wie onvoldoende let op uitlegbaarheid, overdraagbaarheid en exit-mogelijkheden, ruilt vaak kortetermijngemak in voor langetermijnverlies aan controle.
Wat sterk was aan deze sessie, is dat soevereiniteit niet werd gebracht als modewoord, maar als ontwerpprincipe. Eigenaarschap van data, eigenaarschap van logica en eigenaarschap van oplossingen vormen samen de basis om bestuurbaar te blijven. Daarbij werd ook expliciet gemaakt dat governance en datamanagement geen technische producten zijn, maar doorlopende processen die door de architectuur ondersteund moeten worden. Dat is precies het onderscheid dat ertoe doet. Een platform lost governance niet op, maar kan governance wel afdwingbaar, zichtbaar en werkbaar maken.
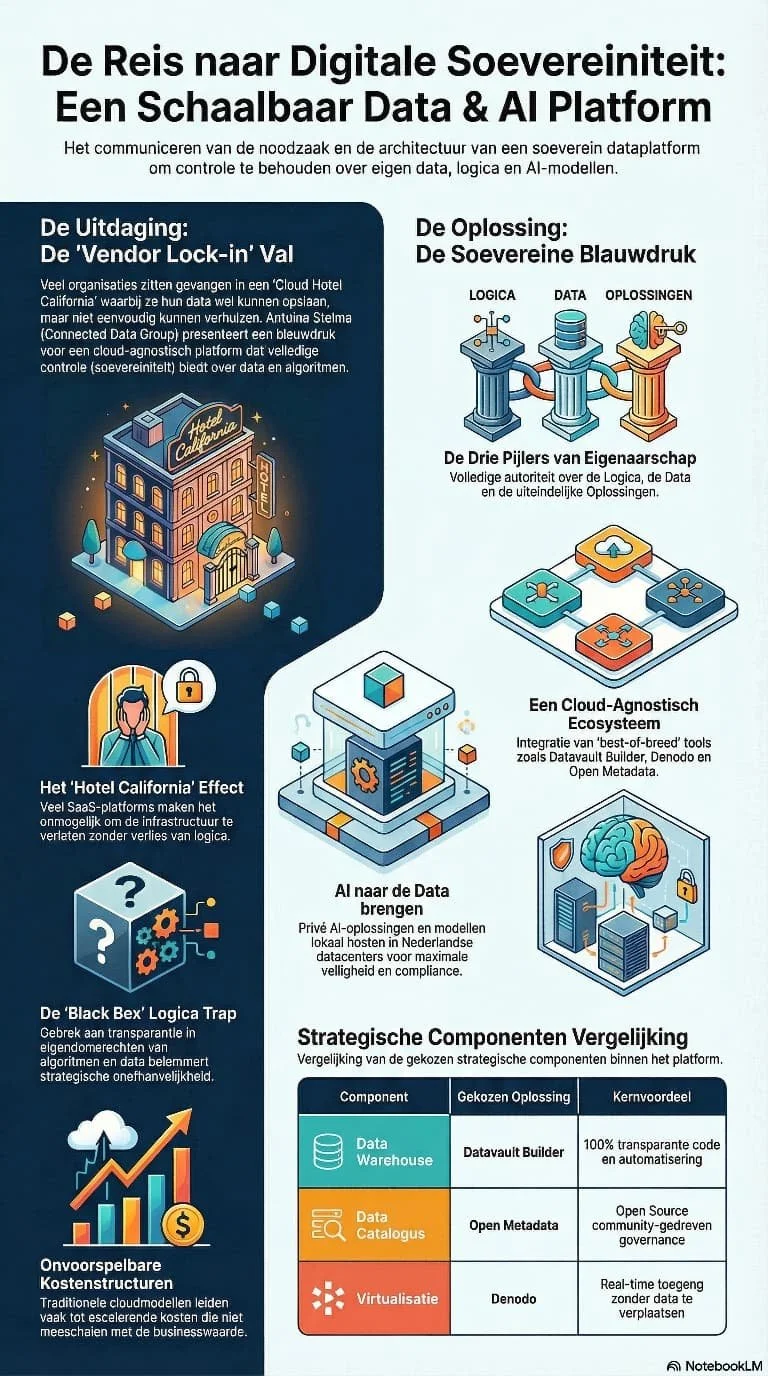
Impressie van de presentatie van Antoine Stelma over Digitale Soevereiniteit.
Alec Sharp sloot de dag af met een sessie die inhoudelijk misschien wel een van de belangrijkste bijdragen leverde. Zijn verhaal over concept modelling with normal people was in wezen een pleidooi om opnieuw te beginnen bij taal, begrip en herkenning. Niet bij formele definities, niet bij methodische colleges, maar bij de woorden die mensen in hun eigen werk gebruiken. Dat is een les die in veel data-omgevingen nog steeds onvoldoende wordt toegepast.
Zijn uitgangspunt was eenvoudig: begin met een gesprek. Laat mensen termen noemen die zij dagelijks gebruiken. Vraag welke informatie ze missen of niet vertrouwen. Bouw van daaruit verder. Dat lijkt bijna te simpel, maar het raakt precies de kern van veel semantische problemen in organisaties. Begrippen worden vaak pas problematisch als men doet alsof ze al helder zijn. In werkelijkheid bedoelen verschillende afdelingen vaak iets anders met dezelfde term, of gebruiken ze verschillende termen voor ongeveer hetzelfde verschijnsel.
Dat maakt zijn bijdrage relevanter dan ze op het eerste gezicht misschien leek. Waar veel dataproblemen graag technisch worden gemaakt, herinnerde deze sessie eraan dat een groot deel van de opgave nog steeds begint bij zorgvuldig luisteren, helder benoemen en consequent structureren. Niet alles is een platformvraagstuk. Veel begint nog altijd met betekenis.
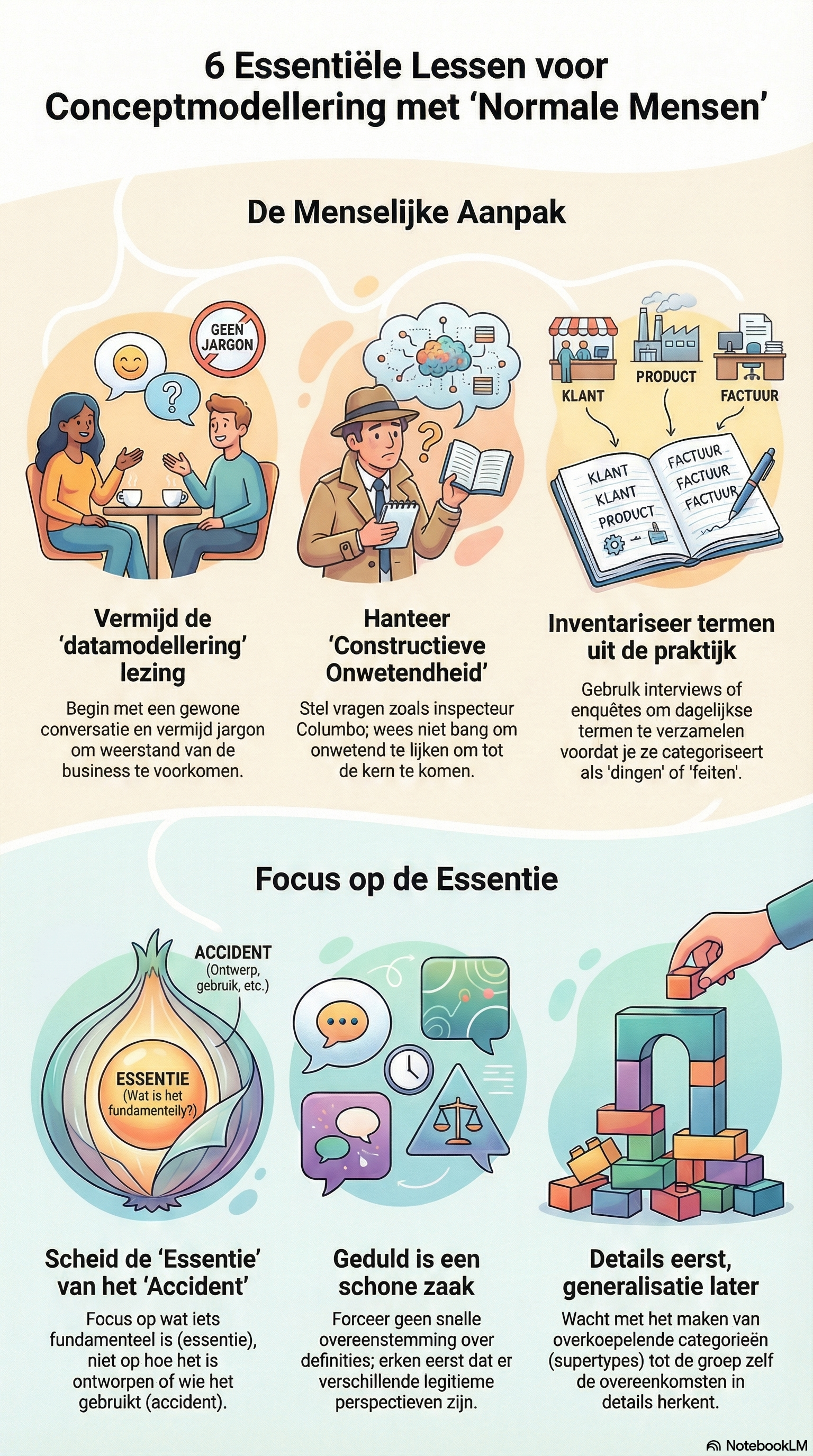
Impressie van de sessie van Alec Sharp over datamodellering.
Als de dag als geheel wordt overzien, ontstaat een opvallend consistent beeld. De sessies gingen over architectuur, data products, governance, administratie, soevereiniteit en modellering. Wat mij betreft allemaal fundamentele thema’s voor de moderne datagedreven organisatie.
Los van de inhoud was het congres als vanouds prefect georganiseerd met strakke tijdsplanning, heerlijke lunch en gezellige afsluitende borrel. Op naar DWBI Summit 2027!
Opvallend: Gen Z bezoekers waren afwezig, als zo vaak. Een zorgelijke ontwikkeling omdat juist deze nieuwe generatie afhankelijk is, in alle opzichten, van niet alleen AI maar bovenal ook van data, in het dagelijks leven en in hun professionele carrière. Het is dus onbegrijpelijk dat er op de meeste hogescholen en universiteiten hiervoor zo weinig aandacht is. Een van de redenen voor mijzelf om nog meer in te zetten op kennisoverdracht en -ontwikkeling richting de nieuwe generatie Data & AI professionals.
