ABN AMRO data mining case
Learning from the past.
Analytical processes, like data mining and what we now call AI are a smart combination of data and human expertise.
In 1997, I was working as a member of the data mining team involved in the ABN AMRO case. Looking back, what makes this case memorable is not simply that it was early, ambitious, or technically interesting. It is that many of the issues we dealt with then are still the issues organizations struggle with today.
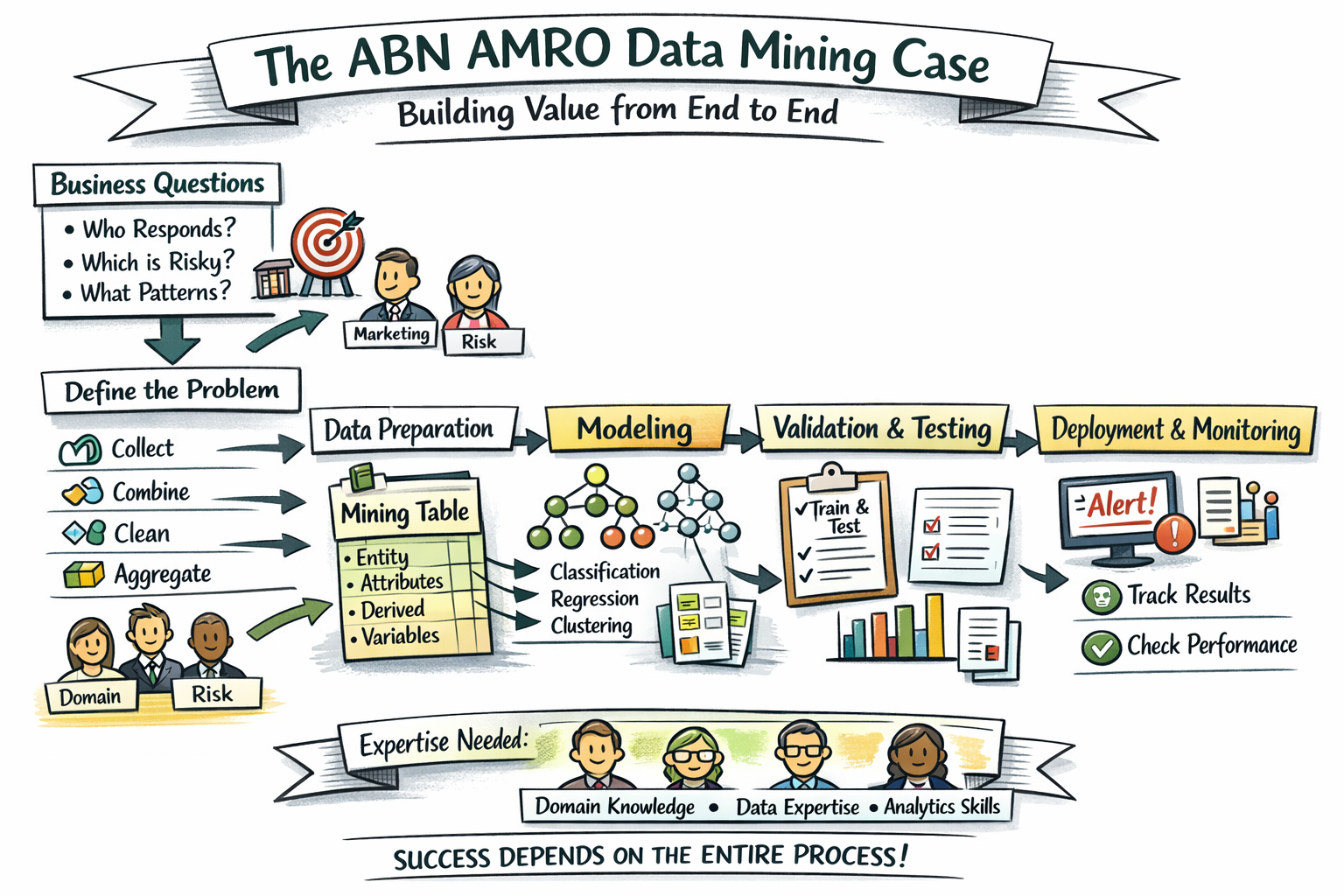
The case was never really about finding one smart algorithm. It was about something much more demanding: how do you turn data mining into a practical capability inside a large bank? How do you move from a business question to a usable analytical dataset, from that dataset to a model, from that model to decisions, and from those decisions to something that can actually be embedded in the organization? That was the real challenge.
What made ABN AMRO a compelling setting was the combination of scale, complexity, and business urgency. There was no shortage of data, no shortage of analytical questions, and no room for academic exercises that produced interesting patterns but no operational value. The business wanted concrete answers. In direct marketing, the question was which customers were most likely to respond. In risk-related domains, the question was which cases were more likely to become problematic. In broader customer analysis, the interest extended to product combinations, behavioral patterns, and segments worth treating differently. In other words, the work started with practical banking questions, not with fascination for technology.
That point matters because it shaped the entire case. We were not searching for a tool that could “do data mining.” We were trying to build an environment in which business questions could be translated into analytical work in a disciplined and repeatable way. That sounds straightforward, but it was anything but simple. Very quickly, it became clear that the hardest part would not be the modeling itself. The hardest part would be the data side of the work.
This is one of the main reasons the case has stayed with me. Even in 1997, the real bottleneck was not the algorithm. It was the construction of the mining table: deciding what the analytical entity should be, selecting relevant data, linking sources, aggregating transaction-level information to the right level, deriving additional variables, dealing with missing values, spotting data quality issues, and making all of that flexible enough to support iterative analysis. That was where the real effort went, and that was also where the quality of the result was largely determined.
Inside the bank, that also created a structural tension. The data warehouse function had its own responsibilities, timelines, and constraints. At the same time, data mining is by nature iterative. Analysts rarely know at the beginning exactly which aggregations, transformations, or derived variables will be needed. New insights emerge during the work, and the dataset often has to evolve with the analysis. That can easily become a problem in a large organization. If every change has to go back to a central team, the process slows down. If everything is left to the analysts, consistency and control disappear. The ABN AMRO case forced us to think carefully about that balance.
The answer was not to choose between centralization and flexibility, but to organize both. The idea was that the central team would create the initial target file or data mart with the most important aggregations already in place. But lower-level source data and keys also had to remain available so that the data miner could still make additional refinements and adjustments where needed. That was an important design principle. It recognized that data mining cannot function if the analytical team is completely dependent on slow central handoffs, but it also recognized that some parts of the data foundation need to be managed centrally to remain reliable. That balance still feels highly relevant.
From a methodological perspective, the scope of the case was broad. The work covered multiple types of analytical problems: classification, regression, clustering, association rules, dynamic association rules, structure analysis, and time series analysis. That breadth was important because banking questions do not all look the same. Some require prediction of a class, such as likely responder or likely defaulter. Others require prediction of a value. Others are more exploratory, looking for combinations or structures that matter. What I found particularly interesting at the time was that the discussions were not only about which methods existed, but about which methods were actually useful in a banking context.
Classification quickly emerged as one of the most important areas. That was logical. In banking, many of the most pressing questions are fundamentally classification questions: who will respond, who will not, which cases are low risk, which are high risk, which behaviors deserve attention. Classification trees were especially attractive because they were not only practically useful but also relatively easy to interpret. That was important. In a bank, a model that cannot be explained is much harder to trust, discuss, and operationalize. Regression trees, association rules, and other techniques also had their place, but interpretability was never treated as secondary. It was part of what made an analytical approach viable.
Another thing I remember clearly is that the case made it impossible to think of data mining as a purely technical specialty. Successful work required at least three forms of expertise. There had to be domain knowledge: people who understood the banking process and could frame the business problem properly. There had to be data knowledge: people who knew where the data was, how it could be connected, and what historical quirks or system behaviors might distort interpretation. And there had to be data mining expertise: the ability to choose suitable techniques, prepare the data analytically, and guide the modeling process. When one of those dimensions was weak, the quality of the work suffered. When all three came together, progress was much stronger.
That is also why the case was never just about model building. The process view was much broader. It started with problem identification, moved into data gathering and preparation, continued through model construction and interpretation, and extended into validation, presentation, deployment, and monitoring. That sequence may sound normal today, but at the time it was important to make it explicit. Too many analytical efforts were still focused on the “mining” step in isolation. In this case, it became very clear that mining was only one phase in a much larger chain.
Validation was another serious theme. Even then, it was obvious that a flexible model could look impressive on its training data and still fail to generalize. That is why independent test sets, train/test splits, and ideally cross-validation mattered so much. The goal was not to produce a model that looked good once. The goal was to produce something robust enough to be trusted outside the sample on which it was built. That way of thinking still matters enormously. Many modern discussions about AI sound new, but the underlying issue is the same: a model must prove that it holds up beyond the data that created it.
The intended use of results also shaped the case. Some outputs were meant to support human decision-making through reports, interpretation, and analytical insights. Others were intended to feed into downstream processes, such as campaign selection or other applications. That meant the environment had to support not only analysis, but also reporting, export, and integration. If results could not travel into the rest of the organization, their value would remain limited. This was not treated as an afterthought. It was part of the design from the start.
And then there was monitoring. Once a model is used in practice, it starts to age. Reality shifts. Customer behavior changes. Product landscapes change. Processes change. What looked stable during development can drift over time. In the ABN AMRO case, that was already recognized. Model performance needed to be checked against actual outcomes, and significant deviations needed to be visible. That closed the loop. It made the analytical process continuous rather than one-off.
Looking back, what I take most from the ABN AMRO case is this: data mining only becomes valuable when the whole chain is designed well. The business question has to be clear. The data has to be organized into a workable mining table. The methods have to fit the problem. Different kinds of expertise have to work together. Validation has to be disciplined. Results have to be explainable and usable. And once a model is deployed, it has to be monitored.
That was true in 1997, when I was part of the team working on this case.
It is still true now.
The tools are different. The terminology is different. The scale is larger. But the core lesson has barely changed: analytical success does not begin with the model. It begins with the design of the entire process around it.